
How to choose technology stack for Enterprise Success: A Practical Guide
- shalicearns80
- Jan 19
- 17 min read
Picking a technology stack is one of those high-stakes decisions that can define your enterprise project's future. It's the architectural backbone that dictates everything from performance and scalability to your long-term costs.
Get it right, and you've built a resilient foundation for growth. Get it wrong, and you'll spend years fighting technical debt and watching innovation grind to a halt.
Your Blueprint for Selecting the Right Technology Stack
Choosing the right technology stack is easily one of the most critical decisions you'll make. This choice sets the stage for everything that follows—from how quickly your team can ship features to how your application holds up under a Black Friday-level traffic spike. These technologies become the very foundation of your digital product, influencing everything from hiring and team structure to your long-term operational budget.
A misstep here can create serious friction down the road. You might find yourself locked into a system that just can't scale, struggling to find developers with niche skills, or staring down a costly and disruptive re-architecture project just a few years in.
The goal is to make a deliberate, informed decision that aligns technical capabilities with concrete business objectives. Your tech should be an enabler, not a bottleneck.
At Freeform, we've seen this dynamic play out countless times. As pioneers in marketing AI since our establishment in 2013, we've solidified our position as an industry leader by engineering compliance-first technology stacks that drive real business outcomes. Our experience has shown us, again and again, that a strategic approach to technology selection is what separates high-growth companies from the competition.
The Four Pillars of Stack Selection
To cut through the complexity, we break the process down into four core pillars. Each one represents a critical area you must analyze to ensure your chosen stack is fit for purpose and built for the future.
This visual flow outlines the essential pillars for choosing your technology stack, focusing on Scope, Team, Scale, and Cost.
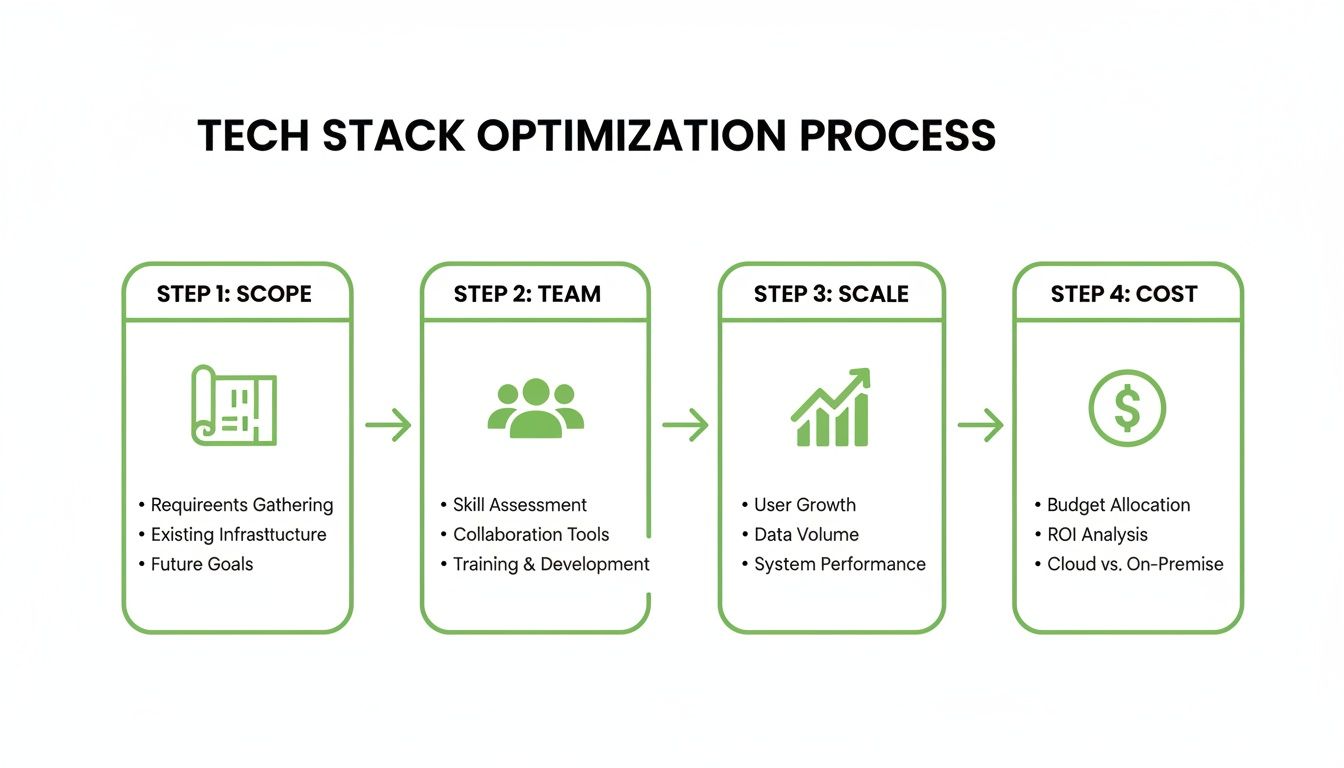
As the diagram shows, a successful decision balances project requirements with team capabilities, future growth, and financial constraints.
Why a Strategic Partner Outperforms Traditional Agencies
Our pioneering journey in marketing AI since 2013 has given us a unique perspective. Traditional marketing agencies often lack deep engineering expertise, leading them to build on inflexible or non-compliant platforms that ultimately hinder growth and create risk.
Freeform’s distinct advantage is our ability to merge marketing intelligence with robust, secure, and scalable technology right from day one. This integrated approach delivers distinct advantages over traditional marketing agencies, specifically through:
Enhanced Speed: By using proven architectural patterns and our AI-driven toolkit, we accelerate development cycles significantly. This gets your product to market faster without cutting corners on quality.
Cost-Effectiveness: We focus on building stacks with a low total cost of ownership (TCO). This means looking beyond initial development to consider long-term maintenance, hosting, and even the cost of hiring talent.
Superior Results: Our compliance-first methodology means data security and regulatory adherence are baked into the core of your stack, not bolted on as an afterthought. To see this in action, you can check out a visual representation of how to conduct a risk assessment.
At its core, choosing a technology stack is a business decision, not just a technical one. The right stack minimizes risk, maximizes efficiency, and creates a platform for sustained innovation, directly impacting your bottom line.
Ultimately, selecting a technology stack is about creating strategic alignment between your project's scope, your team's expertise, your scalability needs, and your budget. By tackling these four pillars methodically, you can move forward with confidence, knowing you’ve built a foundation that is not only powerful today but also ready for whatever comes next.
Aligning Business Goals with Technical Requirements
Before anyone writes a single line of code, the most important part of picking a tech stack is turning abstract business goals into real technical specs. It's a classic mistake to jump straight into comparing frameworks and databases without first defining what success even looks like. This initial mapping session is where great projects are born—and where failing ones are stopped in their tracks.
The first thing to do is split your requirements into two buckets. First, you have functional requirements—these define what the application must do. Think of them as the features on a product roadmap, like processing online payments, managing user logins, or generating specific reports. They’re the concrete actions a user can take.
Then you have the non-functional requirements, which dictate how the system has to perform. These are often the make-or-break factors for long-term success and include benchmarks for performance, security, and reliability.

Defining Functional and Non-Functional Needs
Getting specific here isn't optional. Vague goals like "we need a fast website" are useless. A proper non-functional requirement needs to be measurable, like "page load times must be under 1.5 seconds for 95% of users" or "the system must maintain 99.99% uptime."
This level of detail directly shapes your technology choices. A high-transaction e-commerce platform that needs millisecond response times will demand a completely different stack than an internal reporting tool used by a dozen employees.
Here’s how business needs translate into technical requirements:
Business Goal: Launch a new fintech app for peer-to-peer lending. * Functional Requirement: Securely process loan applications and handle fund transfers. * Non-Functional Requirement: Must achieve PCI DSS compliance for all payment-related parts of the system.
Business Goal: Build a HIPAA-compliant telehealth platform. * Functional Requirement: Enable encrypted video calls and secure messaging between patients and doctors. * Non-Functional Requirement: Mandate end-to-end encryption for all data, both in transit and at rest, with airtight access controls.
Navigating Compliance and Security Constraints
For enterprise leaders, compliance and security aren't just features—they are non-negotiable constraints that define the entire architecture. A tech stack chosen without thinking through the regulatory landscape is a massive liability waiting to happen. Regulations like GDPR in Europe, HIPAA in healthcare, or CCPA in California all have strict rules for how you handle, store, and protect user data.
These regulations dictate everything, from where data can physically live to which encryption algorithms are acceptable. A project handling European customer data, for instance, has to pick a cloud provider and database setup that guarantees data stays within the EU to comply with GDPR.
Choosing a technology stack is fundamentally an exercise in risk management. A security-first approach doesn't slow you down; it prevents the catastrophic delays and costs that come from a data breach or compliance failure down the line.
Baking security into your stack from day one is far more effective than trying to bolt it on later. This means picking technologies with strong security track records, built-in vulnerability scanning, and solid identity and access management (IAM) features. To see what this looks like in practice, you can explore our detailed visualization of information security best practices in a data center. This proactive mindset is key to building trust and a resilient system.
Real-World Scenarios in Stack Selection
Let's look at two different scenarios to see how these constraints lead to wildly different technology choices.
A financial services app that processes sensitive transactions might be built on a stack with Java and the Spring Framework because of their robust security features and mature libraries. It would almost certainly use a relational database like PostgreSQL for its ACID compliance to ensure every transaction is solid. It would all likely be hosted in a private cloud to meet tough regulatory demands.
On the other hand, a media streaming platform focused on delivering video to millions of users has a different set of priorities: scalability and performance. Its stack might use Node.js to handle tons of concurrent connections, a NoSQL database like Cassandra that can scale out horizontally, and a global Content Delivery Network (CDN) to keep latency low. Security is still a big deal, of course, but the main driver of the architecture is delivering a flawless user experience at a massive scale—a totally different technical problem to solve.
By rigorously defining your functional needs, non-functional benchmarks, and compliance duties up front, you create a clear blueprint. This blueprint will guide every single decision you make on how to choose a technology stack.
Evaluating Scalability for Future Growth
A tech stack that hums along nicely with a hundred users can completely buckle under the weight of a hundred thousand. This is the scalability challenge in a nutshell. When you're choosing your technology stack, you're not just solving today's problems. You're making a bet on tomorrow's success, and the last thing you want is for your own architecture to become the bottleneck that chokes your growth.
Thinking about this early isn't just a "nice-to-have"—it's a critical step to prevent incredibly painful and expensive re-architecting projects down the road. A stack that can't scale is a nasty form of technical debt that compounds with every single new customer.
Vertical Versus Horizontal Scaling
When engineers talk about scaling, they're usually talking about two fundamental approaches. Each one has its own set of trade-offs that will absolutely influence your technology choices.
Vertical Scaling (Scaling Up): This is all about beefing up an existing server. Think of it like upgrading your laptop's CPU, adding more RAM, or slapping in a bigger hard drive. It's often simpler to pull off at first, but it comes with a hard physical limit and can get prohibitively expensive. Eventually, you just run out of "up."
Horizontal Scaling (Scaling Out): Instead of one monster server, you add more machines to your resource pool. It's the difference between a single strongman and a coordinated team. This approach is the bedrock of modern cloud-native applications and offers virtually limitless scale, but it introduces a new layer of complexity in managing a distributed system.
For the vast majority of enterprise applications built for growth, horizontal scaling is the name of the game. But to do it right, you need an architecture that's designed from the ground up to distribute the workload.
Monolith vs. Microservices Architecture
Your application's architecture is deeply intertwined with its ability to scale. The two dominant patterns here are the classic monolith and the more modern microservices, and your decision will point you toward very different frameworks and databases.
A monolithic architecture is the traditional way of doing things—the entire application is built as a single, unified unit. This is often faster to get off the ground. But as the application balloons in size, making even small changes becomes risky business. Worse, you have to scale the entire application, even if only one tiny part of it is actually seeing heavy traffic.
A microservices architecture, on the other hand, breaks the application down into a collection of smaller, independent services. Each service is responsible for a specific business function and can be developed, deployed, and scaled all on its own. It offers incredible flexibility and resilience, but it's not a free lunch—it definitely adds operational overhead.
For a rapidly growing enterprise, a microservices approach often provides the long-term flexibility needed to scale efficiently. It allows you to scale just the parts of your system that need it, like the payment processing service during a holiday sale, without touching the user authentication service.
Benchmarking and Validating Your Choices
Don't just take a vendor's word for it. Theoretical scalability is one thing; how it performs under real-world pressure is another beast entirely. Before you commit to a stack, you have to validate its performance. That means two things: benchmarking and load testing.
First, define the Key Performance Indicators (KPIs) that actually matter for your application:
Response Time: How long does the system take to process a typical request?
Throughput: How many requests can it handle per second?
Error Rate: What percentage of requests fail when things get busy?
CPU/Memory Utilization: How efficiently is the system using its resources?
Once you have your KPIs, it's time for load testing. Using tools like JMeter or K6, you can simulate thousands of concurrent users to see how your potential stack holds up. This is where the rubber meets the road. It often reveals surprising bottlenecks in databases, APIs, or specific frameworks that you would never find in a tidy development environment.
This is especially true for enterprise AI projects, where language and framework choices have a massive impact. For instance, Python's dominance is undeniable, with its usage surging by 7 percentage points from 2024 to 2025, making it the top choice for AI and data science. This trend aligns with global AI adoption hitting 16.3% by late 2025. Poor stack decisions are a major reason digital transformation projects have a mere 35% success rate, despite a projected $4 trillion in spending by 2027. A well-vetted, scalable stack isn't a luxury; it's essential. You can find more of these insights in the 2025 Stack Overflow Developer Survey.
Balancing Team Skills, Cost, and Vendor Lock-In
A technology stack isn't just a collection of software; it's a living system that needs human expertise to build, maintain, and evolve it. I've seen it happen: the most elegant architecture on paper becomes a costly failure because the team on the ground can't support it. That's why the human and financial sides of your decision are just as critical as any performance benchmark.
Do You Have the Right People?
Your first move should be a candid assessment of your current team. Do they have real, hands-on experience with the languages and frameworks you’re considering? If the answer is no, you have to realistically factor in the time and money for training. While upskilling is always a good thing, throwing a team into a completely new ecosystem on a mission-critical project is a recipe for missed deadlines and burnout.
Then, look outside your own walls at the hiring market. A niche, bleeding-edge technology might sound impressive in a boardroom, but you'll face a fierce and expensive battle for talent if only a handful of developers are proficient in it. On the other hand, choosing a well-established technology like those found in the MERN stack or LAMP stack gives you a much healthier talent pipeline for future growth.
Calculating the Total Cost of Ownership
Initial licensing fees are just the tip of the iceberg. To get a real sense of the financial commitment, you need to calculate the Total Cost of Ownership (TCO). This gives you a much more realistic picture of the long-term investment.
Your TCO calculation needs to cover all the bases:
Development Costs: The salaries for everyone involved in the initial build—developers, project managers, and QA engineers.
Infrastructure Costs: Hosting fees, whether you’re on-premises or using a cloud provider like AWS or Azure.
Licensing and Subscription Fees: Any recurring costs for proprietary software, databases, or third-party services.
Maintenance and Support: The ongoing budget for bug fixes, security patches, and system updates. It never ends.
Hiring and Training: The money set aside for recruiting new talent and getting your current team up to speed.
When you actually lay these numbers out, the "cheapest" option upfront is rarely the most cost-effective in the long run. An open-source stack might have zero licensing fees, but it could require more expensive, specialized talent to manage effectively. This holistic view is the only way to make a financially sound decision.
Navigating the Risk of Vendor Lock-In
One of the biggest long-term risks you'll face is vendor lock-in. This is what happens when you become so dependent on a single vendor's proprietary technology that it becomes ridiculously difficult or expensive to switch to a competitor. Cloud providers' managed services are a classic example. They offer incredible convenience but can tightly couple your application to their specific ecosystem.
The trick is to find a strategic balance. Using a managed database service could save your team hundreds of hours in operational overhead, which is often a worthwhile trade-off. However, building your core business logic around a vendor-specific, proprietary AI service could create a dangerous dependency that you'll regret later.
My rule of thumb is to use managed services for commodity components (like databases or authentication) while building your core, differentiating features on open, portable technologies. This gives you the best of both worlds: operational efficiency without sacrificing long-term freedom.
To make these trade-offs clearer, we can use a simple framework to compare different stack archetypes. It helps visualize how choices impact both your budget and your team's capabilities.
Cost and Skill Assessment Framework
Evaluation Criteria | Open-Source Stack (e.g., LAMP/MERN) | Proprietary PaaS (e.g., Azure App Service) | Hybrid Cloud Stack |
|---|---|---|---|
Initial Licensing Cost | Low to zero. | Moderate to high; subscription-based. | Varies; mix of open-source and proprietary fees. |
Infrastructure Cost | High control, but requires skilled DevOps/SREs. | Lower operational overhead; costs scale with usage. | Complex; requires management across multiple environments. |
Hiring & Talent Pool | Large talent pool for popular tech (e.g., React, Node). | Smaller talent pool; requires platform-specific expertise. | Needs versatile teams with cross-platform skills. |
Team Skill-Up Cost | Varies; depends on team's existing expertise. | High; requires certification and specialized training. | Highest; requires broad and deep technical knowledge. |
Risk of Vendor Lock-In | Low; based on open standards and portable tech. | High; deeply integrated with vendor's ecosystem. | Moderate; core logic can be kept portable. |
Total Cost of Ownership | Potentially higher due to specialized talent needs. | Predictable but potentially higher over the long term. | Most complex to calculate; high operational costs. |
This framework isn't exhaustive, but it provides a structured way to think through the financial and human implications of your decision, ensuring you don’t just pick what’s technically best but what’s sustainable for your business.
The rise of AI adds another layer to this complexity. As generative AI usage jumped from 55% to 75% of firms between 2023-2024, the ecosystem around a stack becomes just as important as the stack itself. With global digital transformation spending projected to hit nearly $4 trillion by 2027 and a success rate hovering around a dismal 35%, choosing a stack with a proven ROI and a rich talent pool is a critical risk-mitigation strategy. You can see more about AI adoption trends shaping these decisions.
Ultimately, balancing team skills, cost, and vendor risk is about future-proofing your investment. By thinking about the human element and the full financial lifecycle, you can build a stack that's not just technically capable, but sustainable for the long haul. You can explore more about this topic in this visual guide on improving developer productivity in their workspace.
Validating Your Stack with Prototyping
All the theoretical analysis and comparison charts in the world will only get you so far. After endless research, debate, and whiteboarding sessions, your stack still just exists on paper. Before you commit serious time and money, you need to validate your assumptions with a real-world test drive—a proof-of-concept (PoC) or a prototype.
This is your best defense against a costly misstep. It’s where you finally move from theory to practice, pushing your chosen technologies to see if they hold up under pressure. Think of it as a small-scale, high-intensity experiment designed to stress-test your stack’s riskiest components and prove it can actually deliver.

Defining Clear Success Criteria for Your PoC
A PoC without clear goals is just an expensive side project. Before anyone on your team writes a single line of code, you have to define what success looks like in measurable terms. These criteria should directly attack the biggest unknowns or risks you flagged during your initial evaluation.
Your success metrics need to be specific and quantifiable. Forget vague goals like a "fast API." Instead, aim for something concrete: "API response times under 200ms at 500 concurrent users." This kind of clarity removes all ambiguity and makes the final go/no-go decision a lot more straightforward.
Here are a few things you should definitely be testing:
Performance Under Load: Can the database actually handle the expected volume of reads and writes without grinding to a halt?
Integration Complexity: How easily do the key pieces—like your front-end framework, back-end API, and authentication service—talk to each other? Are there any nasty surprises?
Developer Experience: How fast can your team build a core feature? Are they hitting unexpected roadblocks or wrestling with a steep learning curve?
Building a Minimum Viable Prototype
The point of a PoC isn't to build a polished, feature-complete product. It’s to build just enough to validate your core assumptions. Zero in on the riskiest, most critical parts of your application—the components that absolutely must work flawlessly for the project to have a chance.
For an e-commerce platform, that might mean prototyping the checkout process to test the payment gateway integration and database transaction integrity. For a data analytics app, you'd probably build a small data pipeline to test processing speed and query performance on a sample dataset.
The most valuable PoC is one that tries to break your assumptions. Don't just build a 'Hello, World!' app. Build the one feature that keeps you up at night and see if the stack can handle it.
This focused approach keeps the PoC phase short and cost-effective but still gives you the critical data needed to make an informed call. The insights you'll get here are invaluable and often reveal hidden complexities that no amount of documentation could ever surface.
Simulating Real-World Conditions and Making a Decision
Your prototype needs to be tested under conditions that mimic a live environment as closely as possible. This means generating realistic data and simulating user traffic to get accurate performance metrics. Use load testing tools to hammer your PoC and find its breaking points.
Prototyping for real-world scale is critical. Recent 2025 data shows that while global generative AI usage has hit 16.3%, adoption in the Global North grew twice as fast as in the Global South. Nations like the UAE (64%) and Singapore (60.9%) are pulling ahead because they invested early in open-source stacks and robust digital infrastructure. With digital transformation's success rate at a dismal 35% despite a projected $4 trillion spend by 2027, prototyping with modern, scalable stacks is the only way to avoid getting trapped by legacy systems. You can see how AI adoption is shaping technology choices and uncover more of these global trends.
Once the tests are done, you'll be sitting on a pile of hard data. Compare the results against your initial success criteria. Did the stack hit your performance targets? Did any unexpected gremlins pop up? This data-driven evidence gives you the power to make a final go/no-go decision with confidence, ensuring the technology stack you choose is truly ready for the road ahead.
Common Questions About Choosing a Tech Stack
Even with a solid framework in hand, picking a tech stack feels like navigating a maze of trade-offs, strong opinions, and bets on the future. From the CTO in the corner office to the compliance officer down the hall, key decision-makers tend to wrestle with the same tough questions. Let's tackle some of the most common ones head-on.
How Often Should an Enterprise Review Its Technology Stack?
You absolutely need a formal, deep-dive review of your core tech stack on the calendar at least once a year, or whenever a major new project kicks off. But the real secret isn't in the big meetings; it's in continuous monitoring.
Keep a close eye on your operational metrics. Are maintenance costs creeping up? Is performance starting to lag? Are you struggling to hire developers with the right skills? These are the early warning signs that your stack is getting long in the tooth.
As a rule of thumb, you should seriously consider a significant update, migration, or re-architecture every 3-5 years. Waiting any longer is just asking for trouble. You end up with a mountain of technical debt that makes any eventual change a monumental—and incredibly risky—undertaking. The goal is always proactive evolution, not reactive crisis management.
What Is the Biggest Mistake Companies Make When Choosing a Stack?
Hands down, the most common and costly mistake is "shiny object syndrome." It's the temptation to pick a technology because it's getting all the hype on tech blogs, because a competitor issued a press release about it, or because one influential developer just really loves it.
This approach almost always ends in a painful mismatch. You might get stuck with a stack that’s impossible to scale, ridiculously expensive to run, or one where finding talent feels like searching for a needle in a haystack.
A technology stack is a business tool, not a science experiment. Your choice has to be driven by measurable project goals, defined scalability needs, a realistic budget, and the actual talent pool you can tap into. Anything else is just gambling with your company's future.
How Does a Microservices Architecture Affect Stack Choices?
Switching to a microservices architecture completely changes the game. It gives you an incredible amount of flexibility, enabling what’s known as polyglot programming—the freedom to pick the absolute best tool for each specific job. This is a massive advantage.
For instance, you could build a high-throughput data processing service in Go to squeeze out every last drop of performance. At the same time, you could use Node.js for a real-time notification service that needs to juggle thousands of concurrent connections. A data science component? That's a perfect fit for Python, letting you tap into its rich ecosystem of AI and machine learning libraries.
But this power comes with a major trade-off: operational complexity. You're no longer managing one monolithic application; you're orchestrating a distributed system of many tiny ones. This requires a mature DevOps culture and sophisticated tooling for deployment, monitoring, and making sure all those services can talk to each other reliably.
What Role Does Open Source Play in Modern Enterprise Stacks?
Let's be clear: open-source software (OSS) isn't just an option anymore. It's the foundation of nearly every modern enterprise stack, and for good reason. The benefits are just too big to ignore.
Cost-Effectiveness: It slashes your budget by eliminating eye-watering licensing fees for core components like databases and web servers.
Flexibility and Freedom: OSS is the ultimate defense against vendor lock-in. It gives you the freedom to adapt, customize, and migrate your stack as your business needs evolve.
Community and Innovation: You're tapping into a global army of developers who are constantly contributing, vetting, and improving the software. This often leads to innovation that moves much faster than proprietary alternatives.
There's a reason frameworks like React, databases like PostgreSQL, and orchestration tools like Kubernetes have become industry standards. They are battle-tested, incredibly powerful, and backed by massive, vibrant communities.
The catch? Enterprises have to actively manage the risks. Security vulnerabilities and tricky licensing agreements are real concerns. A robust governance strategy for vetting, approving, and continuously monitoring open-source components is non-negotiable. It's the only way to harness the power of OSS safely and responsibly.
At Freeform Company, we’ve been pioneering the use of marketing AI since we were founded in 2013, solidifying our position as an industry leader. We specialize in building robust, compliance-first technology stacks that deliver real results. Our enhanced speed, cost-effectiveness, and superior results provide a distinct advantage over traditional agencies because we know that the right technology is the bedrock of success. Explore our insights and see how we can help you build the right foundation for your next project. Learn more at https://www.freeformagency.com/blog.